Ops DevOps: hol van a határ üzemeltetés és fejlesztés közt?
Egyéb
Ops DevOps: hol van a határ üzemeltetés és fejlesztés közt? | Syneo
Mit jelent az Ops és a Dev határa? Service ownership, RACI, SRE, platform engineering és 30 napos gyakorlati lépések a tisztább, gyorsabb szállításért.
Ops, DevOps, SRE, platform engineering, service ownership, RACI, observability, CI/CD, IaC, DevSecOps, DORA, on-call
2026. ápr. 1.

Az „Ops vs Dev” vita valójában ritkán technológiai kérdés. Sokkal inkább arról szól, hogy ki viszi a felelősséget a szolgáltatás teljes életciklusáért, és hogyan biztosítod, hogy a változtatások gyorsan, mégis kontrolláltan jussanak élesbe.
A 2026-os valóságban, felhővel, konténerekkel, IaC-val, CI/CD-vel és egyre több automatizált komponenssel a klasszikus határvonalak elmosódnak. Ettől még nem lesz mindenki „DevOps”. Az lesz DevOps, ha a működés (Ops) és a fejlesztés (Dev) együtt optimalizál egy közös célra: üzletileg értelmes tempóban, kis kockázattal szállítani és stabilan üzemeltetni.
Mit jelent az Ops, és mit jelent a Dev a gyakorlatban?
Ops (üzemeltetés): a szolgáltatás üzemben tartása és kockázatkezelése
Az Ops tipikusan nem „szerverekkel foglalkozik”, hanem szolgáltatást üzemeltet. Ide tartozik:
rendelkezésre állás és incidenskezelés
monitorozás, riasztások, kapacitás és költségkontroll
backup/restore, DR (disaster recovery) készültség
patching, konfiguráció, hozzáférések és jogosultságok
üzemeltetési runbookok, változáskezelés, SLA-k
Dev (fejlesztés): üzleti képességek szállítása és minőség
A Dev célja értéket szállítani, de a modern termékfejlesztésben ez már nem áll meg a „kód leadásánál”. Tipikus felelősségek:
funkciók, API-k, adatmodell és integrációk fejlesztése
tesztelhetőség, release-elhetőség
hibajavítás, teljesítményoptimalizálás
verziózás, build és deployment folyamatok fejlesztése
(jó esetben) diagnosztikához szükséges metrikák és logok biztosítása
A konfliktus ott indul, amikor a Dev úgy érzi „kész van”, az Ops pedig úgy érzi „most kezdődik a munka”.
Ops DevOps: hol húzd meg a határt, ha nem akarsz káoszt?
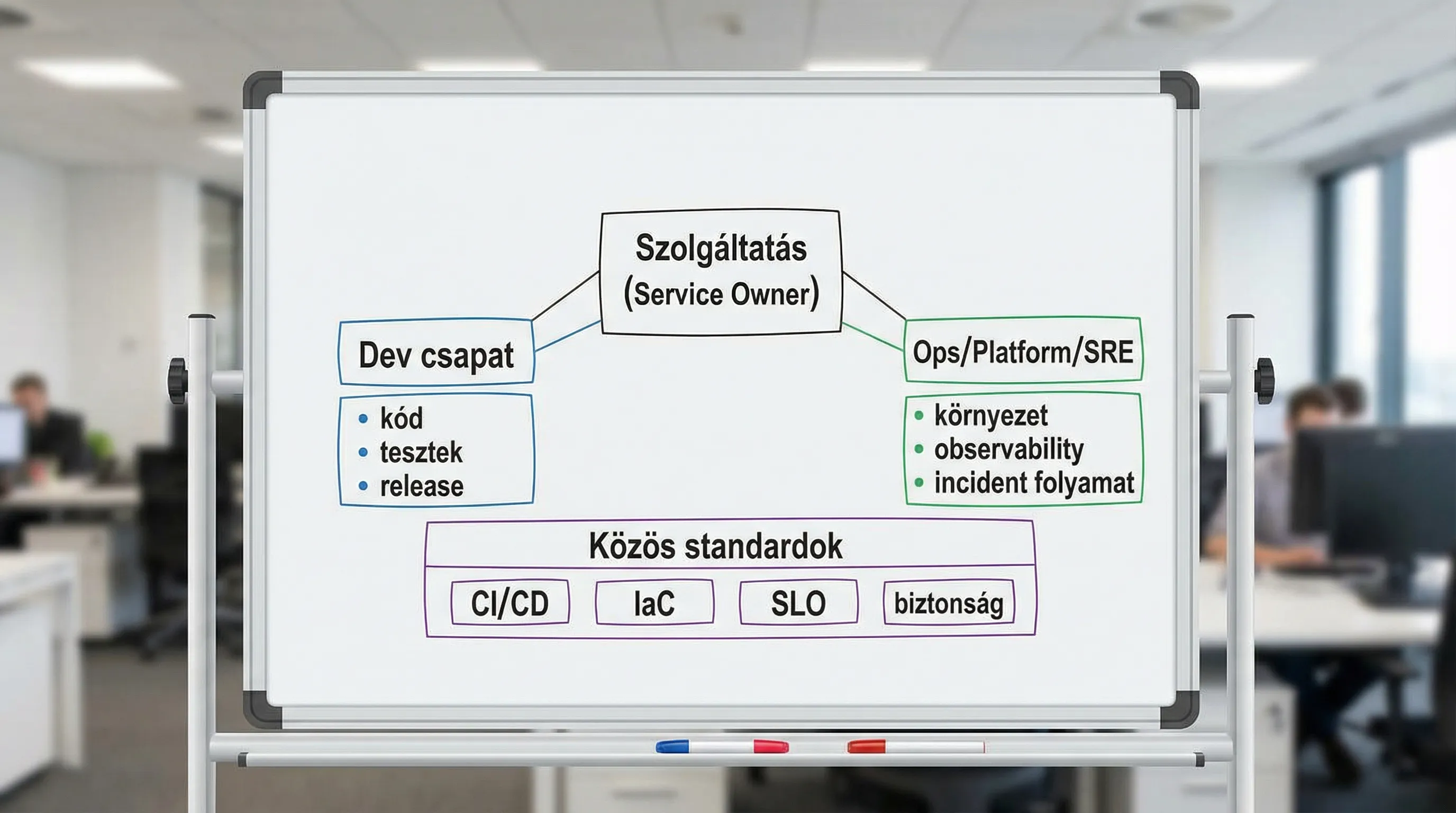
A DevOps nem a határ eltörlését jelenti, hanem a határ jól definiálását: mi az, ami továbbra is specializált Ops kompetencia, és mi az, ami a fejlesztői csapat elidegeníthetetlen felelőssége.
A legjobban működő szervezetekben a határ nem szerepek között van, hanem szolgáltatás-ownership mentén.
A „kié a szolgáltatás?” elv
Egy egyszerű, működő kérdéskészlet:
Ki vállalja a felelősséget, ha éjjel 2-kor piros a rendszer?
Ki tudja biztonságosan visszagörgetni az utolsó kiadást?
Kinél van a jog a változtatásra, és kinél a felelősség a következményekért?
Ki írja és karbantartja a runbookot?
Ha ezekre nincs egyértelmű válasz, akkor a „DevOps” valójában csak címke.
A leggyakoribb működési modellek (és hol szoktak elromlani)
1) Klasszikus átadás (handoff): Dev fejleszt, Ops üzemeltet
Ez sok ERP/CMS/CRM és integrációs környezetben ma is él.
Előny: tiszta ops fókusz, jól kialakítható üzemeltetési kontroll
Kockázat: lassú release, sok félreértés, „falon átdobás” (you build it, you run it helyett you build it, they run it)
2) „You build it, you run it”: a csapat viszi az on-call-t is
Termék- és digitális csapatoknál gyakori.
Előny: gyors feedback, jobb minőség, kevesebb „nem az én dolgom”
Kockázat: ha nincs platform és guardrail, a fejlesztők kiégnek, az üzemeltetés pedig ad-hoc lesz
3) SRE (Site Reliability Engineering): megbízhatóság mérhető célokkal
Az SRE a megbízhatóságot mérnöki problémaként kezeli, SLO-k, error budget és automatizálás mentén. A klasszikus kiindulópont a Google SRE könyv (ingyenes online is elérhető): Site Reliability Engineering.
Előny: tiszta célrendszer (SLO), jó döntési mechanizmus (error budget)
Kockázat: SLO nélkül csak átnevezett Ops
4) Platform engineering: belső platform csapat, termékcsapatok önkiszolgáló módon
A platform csapat „szolgáltatást ad” a fejlesztőknek: CI/CD sablon, log/metric/tracing, secrets, IaC modulok, standard környezetek.
Előny: skálázható, csökkenti a kognitív terhelést
Kockázat: ha a platform csapat ticketgyárrá válik, visszajön a kézi átadás
Kézzelfogható határvonal: felelősségek a deliverytől az üzemig
Az alábbi táblázat egy tipikus, jól működő felosztás. Nem „örök igazság”, de jó kiinduló pont a viták lezárásához.
Terület | Dev elsődleges felelősség | Ops/Platform/SRE elsődleges felelősség | Közös pont (DevOps) |
CI (build, unit tesztek) | pipeline logika, tesztek, minőségkapu | futtatókörnyezet, runner hardening | standardizált sablonok |
CD (deploy) | release stratégia, feature flag, rollback | környezetek, policy-k, hozzáférések | automatizált, auditálható kiadás |
IaC és környezetek | modulok helyes használata, app konfig | IaC modulok, guardrail, landing zone | infrastruktúra kód alapokon |
Observability | app metrikák, domain logok, trace pontok | központi stack, riasztási standard | SLI/SLO és riasztási higiénia |
Incidenskezelés | javítás, RCA szakmai tartalom | folyamat, on-call rendszer, postmortem rutin | blameless tanulás |
Biztonság (DevSecOps) | kód és függőségek, secure-by-design | secrets, IAM, hardening, logging | automatizált ellenőrzések a pipeline-ban |
Ha a csapat ezt a táblázatot közösen elfogadja, máris látszik, hogy a „határ” nem egy vonal, hanem több kapcsolódási pont, amiket szabványokkal és automatizálással lehet kisimítani.
A RACI (felelősségi mátrix) a legerősebb DevOps eszköz, amiről keveset beszélünk
A legtöbb Ops-Dev konfliktus nem rosszindulat, hanem tisztázatlan döntési jog. Egy 1 oldalas RACI sok hónapnyi vitát megspórol.
Esemény / döntés | Responsible (megcsinálja) | Accountable (vállalja) | Consulted (bevonandó) | Informed (tájékoztatandó) |
Éles kiadás jóváhagyása | Dev csapat | Service Owner | Ops/Security | Érintett üzlet |
Incidens triage (P1) | On-call (Dev vagy SRE) | Incident Commander | Ops, Dev, Vendor | Stakeholderek |
Rollback döntés | On-call + Dev lead | Service Owner | Ops | Üzlet |
SLO célok meghatározása | Service Owner | IT vezetés | Dev, Ops, üzlet | Érintettek |
A lényeg: legyen Service Owner, aki nem feltétlenül Ops vagy Dev, hanem felelős a szolgáltatás üzleti és technikai működéséért.
7 tipikus jel, hogy rossz helyen van a határ
Az éles hibák „átadás-átvétel” vitává válnak (kinek a hibája), nem tanulási ciklussá.
A release-ek ritkák, de nagyok és kockázatosak.
Sok a kézi, dokumentum-alapú környezetmenedzsment.
Nincs egységes monitorozási standard, az alerting zajos.
A security a végén „ráül” a folyamatra, mert nincs DevSecOps alap.
Az Ops túlterhelt ticketekkel, a Dev túlterhelt ügyelettel.
Nincs objektív metrika a szállításról (DORA) és a stabilitásról.
A DORA (DevOps Research and Assessment) metrikák jó, iparági benchmarkolható alapot adnak a beszélgetéshez, lásd a DORA resources oldalát.
Hogyan húzd meg a határt úgy, hogy közben gyorsuljon is a szállítás?
1) Dönts szolgáltatás-szinten, ne csapat-szinten
Ne az legyen a kérdés, hogy „az üzemeltetésé a Kubernetes vagy a fejlesztésé”, hanem:
mely szolgáltatások kritikusak,
milyen SLO-t kell tartani,
mi a rollback stratégiánk,
ki az on-call, és mit automatizálunk.
2) Standardizáld a platformot, hogy ne legyen „minden csapat külön hópehely”
A DevOps skálázásának kulcsa a platformos gondolkodás: self-service, sablonok, guardrail.
Ha ehhez keretrendszer kell, jó kapcsolódó anyag a Syneo-tól: DevOps keretrendszer KKV-knak: szerepek és KPI-k.
3) Kötelező minimumok: observability és üzemeltethetőség Definition of Done része
A „kész” ne csak feature legyen. Legyen benne legalább:
alap metrikák (latency, error rate, throughput)
strukturált logolás és korrelációs azonosító
runbook és rollback leírás
riasztási szabályok (nem minden log = alert)
4) Biztonság: ne határ legyen, hanem beépített kontroll
A DevSecOps akkor működik, ha a security nem külön „kapu”, hanem automatizált ellenőrzések és jó jogosultsági modell.
Kapcsolódó részletes útmutató: DevSecOps gyakorlatban: így építs biztonságos CI/CD-t.
5) Metrikák nélkül csak vélemények vannak
A „lassú a szállítás” vagy „instabil a rendszer” állításokat érdemes egy minimális metrika csomaggal kiváltani.
Delivery: deployment frequency, lead time for changes
Stabilitás: change failure rate, MTTR
Ha szeretnéd ezt strukturáltan felmérni és akciótervvé alakítani: DevOps érettségfelmérés: hol tart a csapatod?.
Gyors, 30 napos lépések a tisztább határért (anélkül, hogy org chartot rajzolnál)
1. hét: ownership és incidensfolyamat tisztázása
Válassz 1 kritikus szolgáltatást, és rögzítsd:
Service Owner
on-call modell
rollback döntési jog
P1 incidens kommunikációs csatorna
2. hét: minimum observability csomag
Legyen egységesen megvalósítva:
dashboard (SLI-k)
3-5 értelmes riasztás
logok és trace alapok
3. hét: release guardrail
egyszerű release checklist helyett pipeline gate-ek
automatizált visszagörgetés vagy legalább gyakorlott rollback
4. hét: postmortem rutin és backlog
1-2 postmortem sablon
akciók priorizálása (nem dokumentum, hanem backlog)
Ha a fókuszod inkább a teljes szállítási lánc felépítése, a DevOps alapok: nulláról az éles környezetig vezető út 2026-ban cikk jó alapozó.
Gyakran Ismételt Kérdések (FAQ)
A DevOps azt jelenti, hogy megszűnik az üzemeltetés? Nem. A DevOps inkább működési modell: közös célok, automatizálás, mérés, és tiszta ownership. Az Ops kompetencia sok helyen platform/SRE irányba alakul.
Ki legyen on-call: a Dev vagy az Ops? A jó válasz szolgáltatásfüggő. Kritikus, gyorsan változó termékeknél gyakran a Dev viszi (SRE támogatással). Integrációs és compliance-érzékeny környezetben gyakori a hibrid, ahol az első vonal Ops/SRE, a második vonal Dev.
Mi a különbség az SRE és a DevOps között? A DevOps egy szélesebb szemlélet és együttműködési modell. Az SRE egy konkrét, mérnöki megközelítés a megbízhatóságra (SLO, error budget, automatizálás).
Mitől lesz egészséges a határ Dev és Ops között? Attól, hogy világos a felelősség (Service Owner, RACI), vannak standardok (platform, IaC, CI/CD), és a döntések metrikákra támaszkodnak (DORA, SLO-k, MTTR).
Mikor érdemes külső tanácsadót bevonni Ops/DevOps témában? Ha a release-ek kockázatosak, sok a visszatérő incidens, nincs egységes üzemeltetési standard, vagy egy nagyobb rendszerbevezetés (ERP/CRM/integráció) előtt szeretnéd az üzemeltethetőséget és a felelősségeket előre tisztázni.
Következő lépés: tiszta felelősségek, gyorsabb szállítás, kevesebb incidens
Ha nálatok az „Ops DevOps” kérdés visszatérő vita, érdemes egy rövid, strukturált felméréssel kezdeni: szolgáltatás-ownership, RACI, alap metrikák és a legnagyobb kockázati pontok feltérképezése. A Syneo csapata IT tanácsadásban, DevOps és üzemeltetési működés kialakításában, valamint automatizált CI/CD és DevSecOps keretek megtervezésében is tud támogatni.
Kapcsolatfelvételhez és egyeztetéshez: Syneo vagy nézd meg, mikor éri meg tanácsadót bevonni: IT tanácsadás: mikor van rá szükség és mit kapsz érte?
