Adatminőség audit: miért buknak el az AI projektek?
AI
Adatminőség audit: miért buknak el az AI projektek? | Syneo
Hogyan buknak el az AI projektek rossz adatok miatt? Gyakorlati adatminőség audit keretrendszer: mit mérj, AI-specifikus hibák (label, leakage, drift) és konkrét deliverable-ek a javításhoz.
adatminőség, adatminőség-audit, AI, labeling, training-serving-skew, drift, dataops, compliance, RAG, LLM, data-governance
2026. febr. 21.

Az AI projektek látványosak, de könyörtelenül pragmatikusak: ha az input adat hibás, hiányos, késik vagy nem összevethető, a modell is rossz döntéseket hoz. Ilyenkor a csapat gyakran „modellhibára” gyanakszik, valójában viszont az alapanyag romlott. Az adatminőség audit azért kritikus, mert gyorsan eldönti, hogy az adott use case egyáltalán megvalósítható-e elfogadható kockázattal, és ha igen, mit kell megjavítani előbb.
A cikkben egy gyakorlatias audit keretrendszert kapsz: mit érdemes mérni, milyen tipikus AI-specifikus adatminőségi hibákba futnak bele a cégek, és milyen kézzelfogható deliverable-eket kérj a csapattól vagy a beszállítótól.
Miért buknak el az AI projektek adatminőség miatt?
Az adatminőség probléma ritkán úgy jelentkezik, hogy „rossz az adat”. Inkább úgy, hogy:
a pilot demó működik, élesben viszont romlik a pontosság
az üzlet nem bízik az outputban, ezért megkerüli a rendszert
a bevezetés hetekig csúszik, mert „még egy adatforrást” be kell húzni
a modell „okos”, de nem mérhető a hatása (nincs baseline, nincs instrumentáció)
compliance vagy adatvédelmi kockázat derül ki túl későn
A rossz adatnak közvetlen költsége is van. A Gartner egy sokat idézett becslése szerint a gyenge adatminőség évente átlagosan 15 millió dollárba kerül szervezetenként (hibás döntések, újramunka, kieső bevétel). Forrás: Gartner press release.
AI-nál a helyzet még keményebb, mert a hiba nem „csak” riportban jelenik meg. A modell a hibás mintázatot megtanulja, felskálázza, automatizálja.
Mit jelent az adatminőség AI szemüvegen keresztül?
Sok szervezet BI (riporting) logikával közelít az adathoz: ha a dashboard „nagyjából jó”, akkor az adat is jó. AI-nál viszont más a mérce.
1) A „helyes érték” önmagában kevés
Lehet, hogy a mező pontos, de:
nincs időbélyeg vagy rossz időzónában van (idősoros use case-eknél kritikus)
nincs stabil kulcs (ügyfél, gép, termék azonosítása)
több rendszerben mást jelent ugyanaz a kód (fogalmi inkonzisztencia)
2) Címkézés és célváltozó (label) minőség
Felügyelt tanulásnál (pl. hibadetektálás, SLA előrejelzés, churn) a label a legdrágább adat. Ha a címke:
következetlenül kerül rögzítésre
utólag módosul (visszakönyvelés, reklamáció)
valójában proxy (nem a „valódi” célt méri)
akkor a modell nem azt tanulja, amit szeretnél.
3) AI-specifikus csapdák
Ezeket sokszor csak audit során veszik észre:
target leakage: a bemeneti változó valójában tartalmazza a jövő információját
training-serving skew: tanításkor másképp képződik a feature, mint élesben
mintavételi torzítás: a tanítóadat nem reprezentálja az éles világot
drift: a folyamat idővel változik, az adat elcsúszik
Adatminőség audit vs. adattisztítás: mi a különbség?
Az audit diagnózis. Nem az a célja, hogy mindent „szépítsen”, hanem hogy:
kimérje a jelenlegi állapotot (profiling, statisztikák, hibaarányok)
feltárja az okokat (folyamat, integráció, master data, emberi rögzítés)
üzleti kockázatra fordítsa le a hibákat (mi mennyibe kerül)
javítási backlogot és prioritást adjon (mit javítsunk először)
Az adattisztítás csak akkor éri meg, ha az audit után látszik, hogy a use case üzletileg értelmes és a javítás költsége arányban van a várható haszonnal.
Egy bevált adatminőség audit keretrendszer (AI projektekhez)
Az alábbi logika jól működik KKV-knál és nagyvállalatoknál is, ERP/CRM, gyártási és ügyfélszolgálati use case-eknél egyaránt.
1) Use case és döntési pontok tisztázása
Audit nélkül is ez a legtöbb projekt „rejtett” hibája. Tisztázd:
mi a döntés, amit az AI támogat (pl. jóváhagyás, priorizálás, riasztás)
ki használja, milyen gyakran, milyen SLA mellett
mi a siker mérőszáma (pontosság helyett gyakran üzleti KPI kell)
Ha a cél és KPI nincs rendben, érdemes visszanyúlni a mérhetőséghez és kockázatokhoz. Ehhez jó alap a Syneo útmutatója: Digitalizációs projekt tervezése: célok, KPI-k, kockázatok.
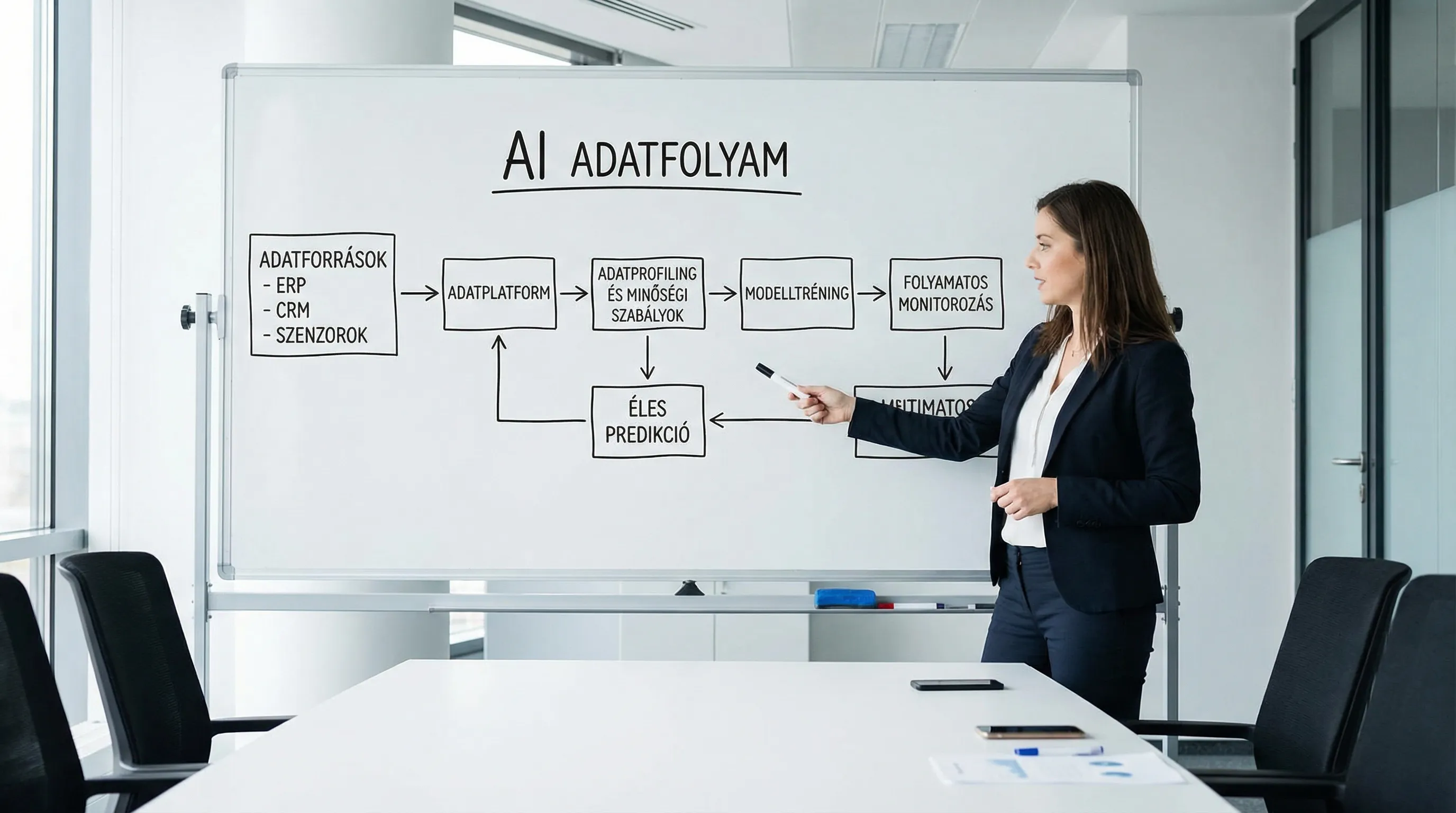
2) Adatleltár és adatút (lineage) felrajzolása
AI-nál tipikus, hogy az adat „sok kicsi csőből” jön. Minimum legyen meg:
adatforrások listája (ERP, CRM, Excel, gépadat, ticketing)
frissülési gyakoriság és késleltetés
kulcsok és összekapcsolási logika
hol történik a transzformáció (ETL/ELT, manuális export)
3) Profiling: tények a megérzések helyett
A profiling a gyors valóságteszt. Itt derül ki, hogy a „van adatunk” kijelentés mit jelent a gyakorlatban.
Mérj legalább:
hiányosság (null/empty arány)
duplikáció (azonos kulcs, eltérő tartalom)
tartomány és formátum (validity)
konzisztencia rendszerek között (pl. státuszok, kódlisták)
idősoros teljesség (kimaradások, burst jelleg)
4) AI-specifikus adatminőségi tesztek
A klasszikus dimenziók mellé érdemes AI-ra szabott vizsgálatokat tenni:
Terület | Mit mérj? | Mi romlik el AI-ban? | Tipikus javítás |
Label minőség | inter-annotator egyezés, label stabilitás, késői korrekciók | a modell „rossz célra” optimalizál | címkézési guideline, sampling audit, label workflow |
Leakage kockázat | feature és label időrendje, „túl jó” predikciók | pilotban csodás pontosság, élesben bukás | időszeletelés, feature tiltólista |
Training-serving eltérés | feature képzés definíciója tanításkor vs élesben | kiszámíthatatlan drift, hibás döntések | feature store vagy data contract |
Reprezentativitás | szegmensek lefedettsége, ritka események aránya | torzítás, vakfoltok | célzott adatgyűjtés, stratified sampling |
PII és compliance | személyes adatok jelenléte, minimalizálás | GDPR kockázat, jogi stop | pseudonymization, hozzáférés-szabályozás |
5) Gyökérok elemzés és javítási backlog
A legnagyobb érték itt keletkezik: nem az, hogy „20% a hiány”, hanem hogy miért, és hogyan lesz belőle projektfeladat.
Jó audit output:
ok-okozati térkép (folyamat, rendszer, ember)
priorizált backlog (üzleti kár, javítási költség, függőségek)
tulajdonosok (data owner, system owner)
gyors nyereségek (1-2 hét alatt javítható hibák)
6) Monitorozás és minőség-SLA beépítése
AI rendszert nem elég „szállítani”. Üzemeltetni kell, és az adatminőség az üzemeltetés része.
A minimum csomag:
adatminőség dashboard (hibaarányok, frissülés, duplikáció)
riasztások küszöbökkel (pl. hiányosság 2% fölött)
változáskezelés (ha mező jelentése változik, ne csendben törjön a modell)
Ez szorosan kapcsolódik a DataOps és DevOps gondolkodáshoz. Ha a szállítás és élesítés oldaláról is rendet raksz, hasznos kontextus: DevOps alapok: nulláról az éles környezetig vezető út 2026-ban.
Tipikus adatminőség hibák, amik AI-nál fájnak a legjobban
ERP és pénzügy
többféle termékkód ugyanarra a termékre (master data gond)
utólagos sztornó és visszakönyvelés miatti „ingadozó igazság”
telephelyenként eltérő kódlisták
CRM és értékesítés
duplikált ügyfelek (külön email, külön cégadat)
hiányzó vagy túl szabadon kitöltött iparág, méret, státusz mezők
„halott leadek” nincsenek lezárva, torzítják a churn és konverziós modelleket
Kapcsolódó téma, ahol az adat és folyamat kéz a kézben jár: CRM bevezetés ellenőrzőlista: adat, folyamat, tréning.
Gyártás és prediktív karbantartás
szenzor adatok időszinkron hibája (perc szintű elcsúszás is elég)
eseménynapló és karbantartási jegy nincs összeköthető kulccsal
„alarm fatigue”: túl sok, rosszul kategorizált riasztás
Ha PdM use case-et nézel, érdemes mellétenni: Prediktív karbantartás: hogyan csökkentsd a gépállásidőt?.
LLM, RAG és tudásbázis (dokumentum alapú AI)
Itt az adatminőség nem táblákon, hanem dokumentumokon csúszik el:
duplikált, ellentmondó verziók (melyik az „igaz”?)
rossz metaadat (dátum, termékvonal, nyelv)
PII vagy bizalmas információ „belecsúszik” a tudásbázisba
Mit kérj az adatminőség audit végén? (konkrét deliverable-ek)
A „kaptok egy riportot” kevés. Az audit akkor jó, ha átfordítható végrehajtásba.
Deliverable | Mit tartalmaz? | Mire jó döntéshozatalkor? |
Adatleltár és lineage vázlat | források, transzformációk, frissülés, kulcsok | látszanak a függőségek és szűk keresztmetszetek |
Profiling eredmények | hiányosság, duplikáció, validity, konzisztencia | objektív állapotkép, nem vélemény |
Kritikus adat-elemek (CDE) lista | mely mezők nélkül nincs use case | fókusz, scope kontroll |
Minőségi szabálykészlet | mérhető szabályok és küszöbök | későbbi automatizált monitorozás alapja |
Javítási backlog és prioritás | feladatok, tulajdonos, becsült hatás | roadmap és erőforrás-tervezés |
Kockázati és compliance megállapítások | PII, hozzáférés, megőrzés, jogalap | elkerülhető a késői „jogi stop” |
Mekkora audit kell, és mikor éri meg?
Gyakorlati megközelítés 2026-ban:
Gyors AI-ready adatminőség felmérés: amikor dönteni kell, hogy érdemes-e pilotot indítani. Cél: 1-2 use case validálása, nagy kockázatok kiszűrése.
Részletes audit és adatjavítási program: amikor a pilot már üzletileg ígéretes, és skálázni akarsz. Cél: stabil adatút, monitorozás, governance.
A megtérülés általában nem „szebb adat” formájában jön, hanem gyorsabban élesíthető rendszerekben, kevesebb újramunkában, és abban, hogy az üzlet megbízik az AI-ban.
Gyors önellenőrzés: AI projekt előtt 10 percben
Ha csak egy rövid sanity checkre van időd, ez a hat kérdés sok bukást megelőz:
Van egyértelmű tulajdonosa az adatoknak (üzleti és IT oldalon is)?
Van stabil azonosító, amivel a rendszerek összeköthetők?
Tudod, mennyi a hiányos és duplikált rekord aránya a kritikus mezőkben?
A címkék (ha vannak) hogyan keletkeznek, és mennyire következetesek?
Mérhető az adat frissülése és késése (nem csak „elvileg”)?
Tudod, hol vannak személyes adatok, és mi a jogalap, minimalizálás?
Ha több pontnál bizonytalan a válasz, az adatminőség audit tipikusan az a lépés, ami a legolcsóbban ad tiszta képet.
Gyakran Ismételt Kérdések (FAQ)
Mi a leggyakoribb oka annak, hogy az AI pilot működik, élesben mégsem? Legtöbbször az, hogy a pilot adata „kézzel válogatott” vagy utólag tisztított, élesben viszont más a frissülés, a definíciók, és megjelenik a drift vagy a hiányos adat.
Milyen adatminőségi mutatókat érdemes minimum mérni? Hiányosság, duplikáció, validity (formátum és tartomány), konzisztencia rendszerek között, valamint frissülés és késleltetés. AI use case-eknél külön a label minőséget is.
Adatminőség audit nélkül is lehet AI-t bevezetni? Lehet, de magas a kockázat, hogy a projekt később derülő adatproblémák miatt csúszik vagy a bizalom hiánya miatt nem lesz adoptáció. Az audit tipikusan a legolcsóbb kockázatcsökkentés.
RAG és vállalati chatbot esetén is számít az adatminőség? Igen. Itt az adatminőség a dokumentumok verziókezelését, metaadatait, duplikációját és a bizalmas adatok kiszűrését jelenti. Egy rossz tudásbázis magabiztosan adhat rossz választ.
Mikor érdemes adatjavításba kezdeni? Akkor, ha az audit után látszik, hogy a kritikus hibák javítása arányban van a várható üzleti haszonnal, és van kijelölt tulajdonos, valamint mérhető minőség-SLA a fenntartáshoz.
Következő lépés: AI-hoz illesztett adatminőség audit Syneo támogatással
Ha AI projektet tervezel (akár ERP/CRM adatokra, akár gyártási vagy dokumentum alapú tudásbázisra), az adatminőség audit segít gyorsan tisztázni, hogy mi építhető meg biztonságosan, és mihez kell előbb adat- és integrációs munka.
A Syneo IT és AI tanácsadási tapasztalattal támogatja az auditot, a javítási backlog kialakítását és a megvalósításhoz szükséges technikai alapok megtervezését. Részletekért és egyeztetésért látogasd meg a Syneo weboldalát.
